MSCN论文总结
利用深度学习进行基数估计
综述
- 基于深度学习来作基数估计,设计了一种MSCN网络model
- 提升了0 Tuple问题的精确度(但没有完全解决0 Tuple 问题)
- 减少了连接join数量变多时的误差
- 使用真实世界IMDb数据集对方法进行了评估,结果表明该方法比基于采样的技术更稳健
需要解决的问题:
- 将查询作怎样的特征化
- 选择何种监督学习算法(设计了怎样的模型)
- 解决“冷启动问题”
将查询作怎样的特征化

我们设Q为查询的全集,$$v(a)表示对a进行one-hot编码,norm(a)表示对a进行标准化$$
$$ q \in Q, q=(T_q, J_q, P_q)$$
$$ T_q=(v(tid), v(samples)), samples可以代表表数量或bitmaps $$
$$J_q=(v(join))$$
$$P_q=(v(col), v(op), norm(val))$$
模型MSCN
对于每一个$$s \in S(S是query特征化后的集合)$$,使用MLP全连接多层神经网络学习,一次处理batch_size数量的查询,对模型输出的结果取平均值作为最终结果。
模型结果会输出一个标准化后的估计的基数,将其恢复为实际数据后与真实数据做比较(做除法)
解决“冷启动问题”
基于模式信息生成随机查询并从数据库中的实际值提取数据来获得初始训练数据集。
- 随机选择一个数$$J_q(0 \le J_q \le 2)$$
- 随机选择一个至少关联一个其它表的表
- 对于$$|J_q|>0$$, 选择一个新表,将join edge加入查询,重复$$J_q$$次
- 随机选择一个数$$P_q(0 \le P_q \le num non-key columns)$$, non-key columns非主键外键的列
- 生成$$P_q$$个predicate
Enriching the Training Data
- Table特征化加入样本数据信息,比如samples的数量或bitmaps(table上对应的predicate)
评估
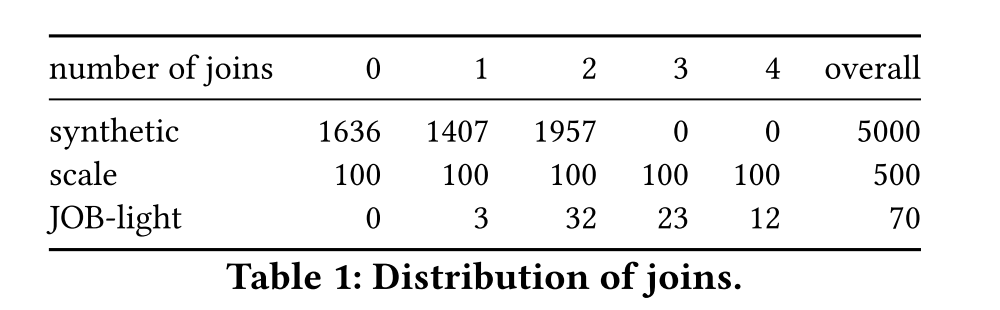
使用了三种数据集
- synthetic workload:合成数据集,最多只有2个join
- scale:0-4个join均有100个
- JOB-light:Join order benchmark上的数据集
0-Tuple问题
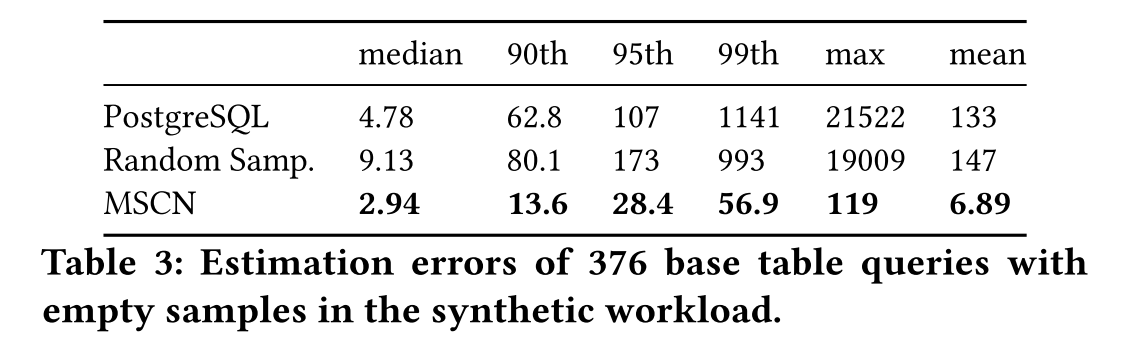
- 0-tuple问题得到了优化,但是并没有彻底解决
有无samples数据对效果的影响
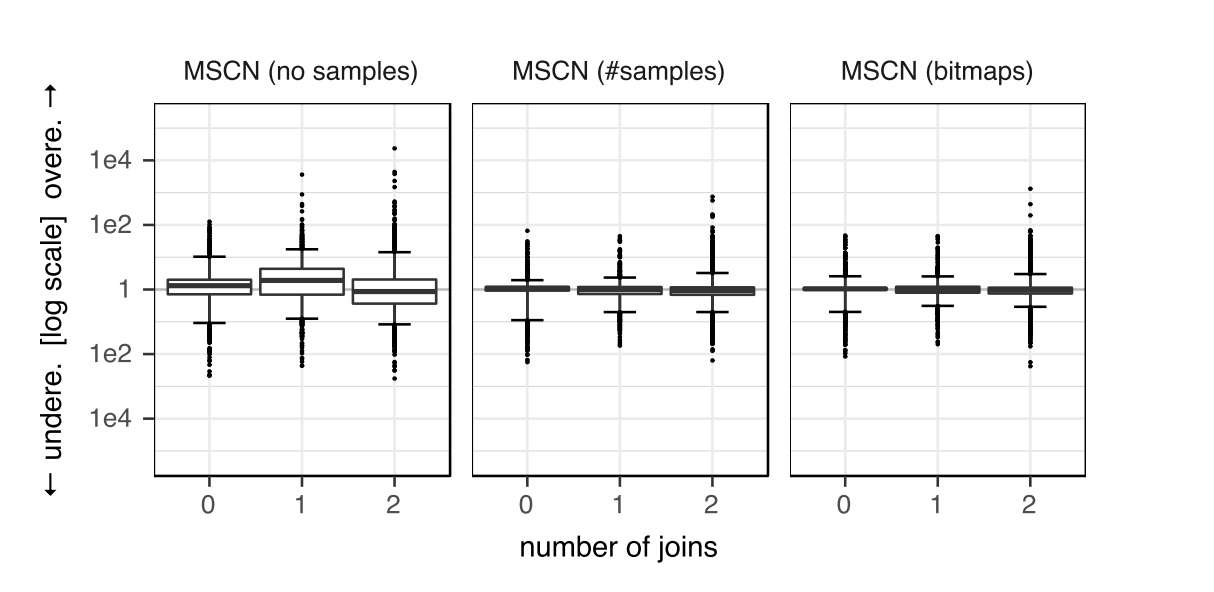
泛化能力的测试
存在的缺点:
- 0-tuple问题不能完全解决
- 多表泛化能力不理想
- 不支持like等查询
MSCN论文总结
http://example.com/2023/03/30/MSCN论文总结/